Do you even know how LLMs work?
What they are, how they work, and how they are trained.
Knowledge of AI methods is not required, this blog post is aimed at anyone that uses or is interested in AI.
What is an LLM?
A Large Language Model (LLM) is a type of machine learning model trained on vast amounts of text designed for text generation. These models are the backbone behind popular products like ChatGPT, Gemini, and Claude.
Conceptually, an LLM can be thought of as a black box, that takes some text as its input, and produces the continuation of that text.
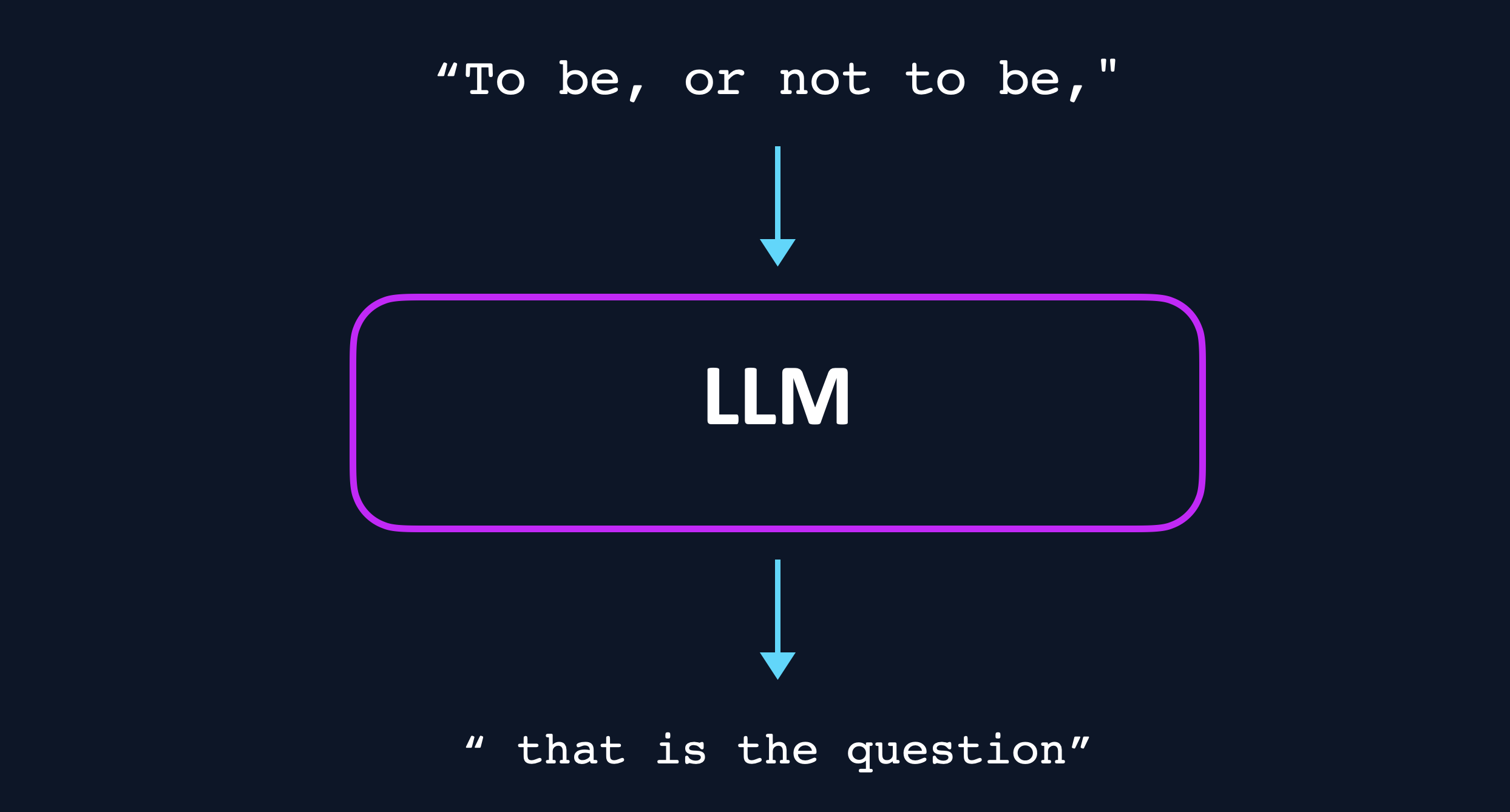
I would describe an LLM as:
the world's most powerful autocomplete
The language of LLMs
LLMs work with tokens, they do not have the concepts of "words", "characters" or "sentences". A token can be one or more characters[1]Some special tokens do not represent any characters at all, we will discuss those later.: Hello is a token, but for example the word "Prehistoric" is split into the tokens Pre and historic[2]All examples use Llama 3's tokenizer. Other tokenizers will give different results..
Shakespeare's famous quote To be, or not to be, that is the question is divided into the tokens ['To', ' be', ',', ' or', ' not', ' to', ' be', ',', ' that', ' is', ' the', ' question']. Each token has its own unique number (its id), for example, the above tokens translate to [1271, 387, 11, 477, 539, 311, 387, 11, 430, 374, 279, 3488].
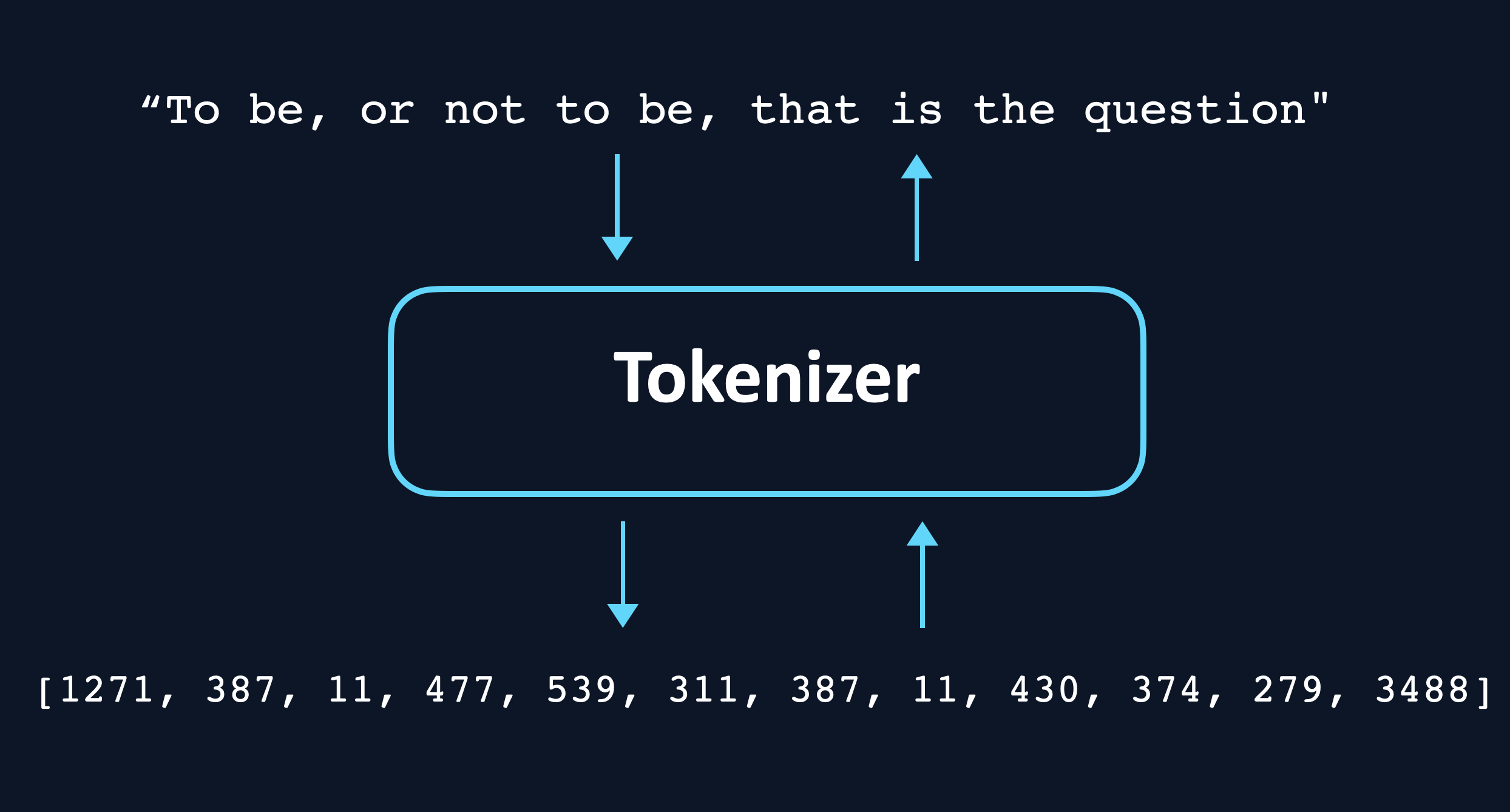
The tokenizer is the piece of code responsible for converting text into tokens (encoding), as well as converting tokens back into text (decoding). [3]If you want to see tokenization in action and play with it you can go to the great site Tiktokenizer.
Different tokenizers may assign different ids to the same tokens, so an LLM will usually only work with the tokenizer it was trained with, and return garbage if it receives token ids from another tokenizer.
Tokenizers have a limited size, Llama 3's tokenizer has 128,256 unique tokens. Once an LLM is trained with a tokenizer, this list of tokens is referred to as the vocabulary of the LLM. An LLM can never accept tokens that are not in their vocabulary, and it is impossible for them to output anything that is not in their vocabulary.
Tokens ids are the fundamental language that LLMs speak, they expect token ids as inputs, and they produce token ids as outputs.
How do LLMs work?
The process for generating text with an LLM is conceptually simple. First the text to be completed must be tokenized. Our text
To be, or not to be, is encoded into its corresponding token ids: [1271, 387, 11, 477, 539, 311, 387, 11]. The token ids are then given to the LLM as input, it processes them, and then chooses the next token. In this case 430. This token id is then added to the original list of token ids and the process is repeated.
How a token is actually chosen
LLMs do not directly output token ids, they output the probability of each token id in the vocabulary being the next token. The output of an LLM defines a probability distribution over the token ids given the input tokens. Llama 3, for example, returns 128,256 probabilities.
The process of choosing a specific token id from the probability distribution over all possible next token ids is called sampling. The simplest way to sample is to simply pick the token id that has the highest probability. The choice of sampling procedure can have large effects on the output of an LLM, and is something that must be carefully tuned when using LLMs to solve specific tasks.
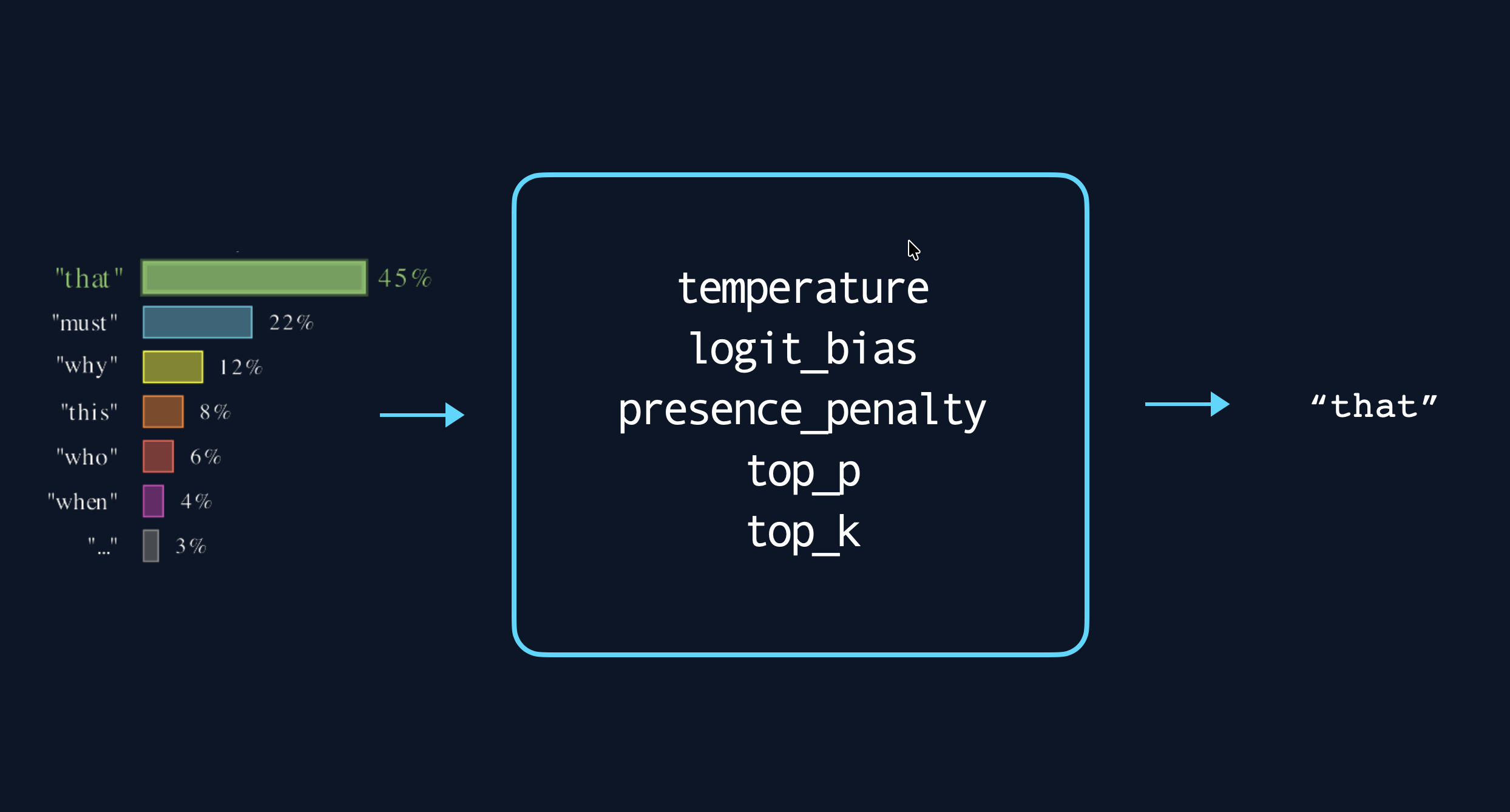
Options usually exposed by LLMs to adjust the sampling procedure [4]vLLM SamplingParams contains a more complete list of available parameters
One crucial point to take away is that regardless of their amazing capabilities and near magical appeal:
The only thing LLMs do is predict the next token
Everything else is accomplished by cleverly framing problems as token prediction.
From monkeys to autocomplete, how LLMs are pre-trained
When an LLM is first created, it's like a monkey with a typewriter; regardless of what text you give it, it will return a random token id.
The goal of pre-training is to imbue an LLM with "general knowledge": what language looks like, what code looks like, facts, how mathematical calculations are performed, etc. This is achieved by training the LLM to complete text, ideally all text.
First, we must find a dataset that is representative of the kinds of text we wish the model to complete. Companies like OpenAI, Google and Meta have their own proprietary datasets, which are a mix of text from the internet, books, scientific articles, code, etc. These training datasets are on the order of trillions of tokens, which is in the same order of magnitude as the text contained in all books ever published.
The process for pre-training the LLM is as follows:
- Sample an example at random from the dataset
- Pass the first N tokens of the example through the LLM
- Increase the probability of the (N+1)th token
- Repeat
This process takes an enormous amount of compute, in the form of thousands of GPU servers, working for months.
Assistants, completing a different kind of text
Once an LLM has been pretrained it is only capable of completing text. What would happen if we were to ask it to "Write a poem"? LLMs are pretrained on a vast amount of text data, we can imagine that the model has seen high school English homework and Reddit threads where the text "Write a poem" is followed by " about your first love", or " for a friend". So a pretrained LLM will respond with something along those lines.
If we want the LLM to actually write us a poem, further training is required. This is achieved through instruction fine-tuning.
Instruction fine-tuning frames the problem of instruction following into something that LLMs do understand, text completion.
The first step is to create a dataset of the kinds of instruction-response pairs we wish the LLM to be able to follow. For example:
| Instruction | Response |
|---|---|
| What is the capital of France? | The capital of France is Paris. |
| What are the three primary colors? | The three primary colors are red, blue, and yellow. |
| Write a short story in third person narration about a protagonist who has to make an important career decision. | John was at a crossroads in his life. He had just graduated college and was now facing the big decision of what career... |
Then, the problem is framed in terms of text completion by modifying the dataset. Here we introduce two special tokens that demarcate the instruction and response part of the text. Text between two <USER> tokens is the instruction, and the text between <ASSISTANT> tokens is the expected response [5]These are special tokens, and cannot be detokenized to text. The token ids for the text "<USER>" is not the same as the token id of the special token <USER>. The first example in the dataset would be rewritten as:
<USER>What is the capital of France?<USER><ASSISTANT>The capital of France is Paris.<ASSISTANT>
This is the new kind of text that the LLM must learn to complete. The LLM is trained in a similar fashion as during pre-training, to simply complete this new type of text we have created.
Resolving ambiguity with human preferences
Consider the instruction: Explain why the sky is blue. An instruction fine-tuned model could respond in many valid ways:
- Rayleigh scattering of sunlight by Earth's atmosphere preferentially disperses shorter wavelengths...
- The sky is blue because the air scatters blue light from the sun more than other colors.
- Great question! So, imagine sunlight is like a bag of mixed candy...
All three are correct but they feel different. The first one is overly technical, the third one sounds almost condescending. The second one is probably what most people want. An instruction fine-tuned model has no way of knowing which one to prefer, they are all equally valid.
The solution, of course, is to generate answers that humans prefer! This is achieved by aligning the LLM with the preferences of humans, as defined by humans themselves.
The human preference dataset consists of examples with three components: one instruction and two possible responses.
| Instruction | Response 1 | Response 2 |
|---|---|---|
| Explain why the sky is blue | Rayleigh scattering of sunlight by Earth's atmosphere... | The sky is blue because the air scatters blue light from... |
| What are the three primary colors? | The three primary colors are red, blue, and yellow. | Red, yellow, and blue (RYB). |
| Write a short story in third person narration about a protagonist who has to make an important career decision. | John was at a crossroads in his life. He had just graduated college and was now facing the big decision of what career... | There was once a man. The man was called John. John was worried about whether he should stay at his current job... |
Humans are then tasked with choosing which response they prefer. This is done for thousands or millions of examples, gathering a diverse dataset of preferences on different topics, tasks, and from different humans. The model is then trained to prefer the same response as the human chose.
The training procedure is fundamentally different from previous training steps: instead of training the model to correctly predict the next token, it is trained to correctly predict full responses.
- Sample an example at random from the dataset
- Pass the instruction tokens of the example through the LLM
- Increase the probability of the favoured response
- Decrease the probability of the disfavoured response
- Repeat
The best autocomplete
Once an LLM has gone through pre-training, instruction fine-tuning and alignment to human preferences we are left with a model that is capable of writing poems, solving math problems, writing code, and importantly, adhering to human preferences. However, it is important to keep in mind that the LLM still does exactly what it was trained to do: generate the next token.